Claude Code が「だめだだめだ」を積んでいた — プロンプト改善のドメイン知識を疑った話
ある創作プロンプトで、ある占いプロンプトで、Claude Code が訂正を受けるたびに禁止条項を足していくのを見た。指摘して reject したが、別の場でも同じ動作をする。そこから「Claude Code はプロンプト改善のドメイン知識を持っていないのでは」という疑惑が立った。「だめだだめだでいい子は育つか」を 4 分野で辿り、Claude Code が積んだメモリを grep し、Claude Code を補えるツールを 3 つ探した結果のメモ。
エージェント基盤を組んでいると、プロンプトの良し悪しがパイプライン全体の品質を直接決める。各ステップが LLM 呼び出しで、入力プロンプトの質がそのまま下流に伝播する設計だと、上流のプロンプトの腐りが系全体の腐りになる。だからプロンプトを書く・直すという作業は、エージェント基盤開発の中心にある仕事のひとつだ。
その前提で、ある創作プロンプトを Claude Code と一緒に書いていて、こういう動きに気づいた。
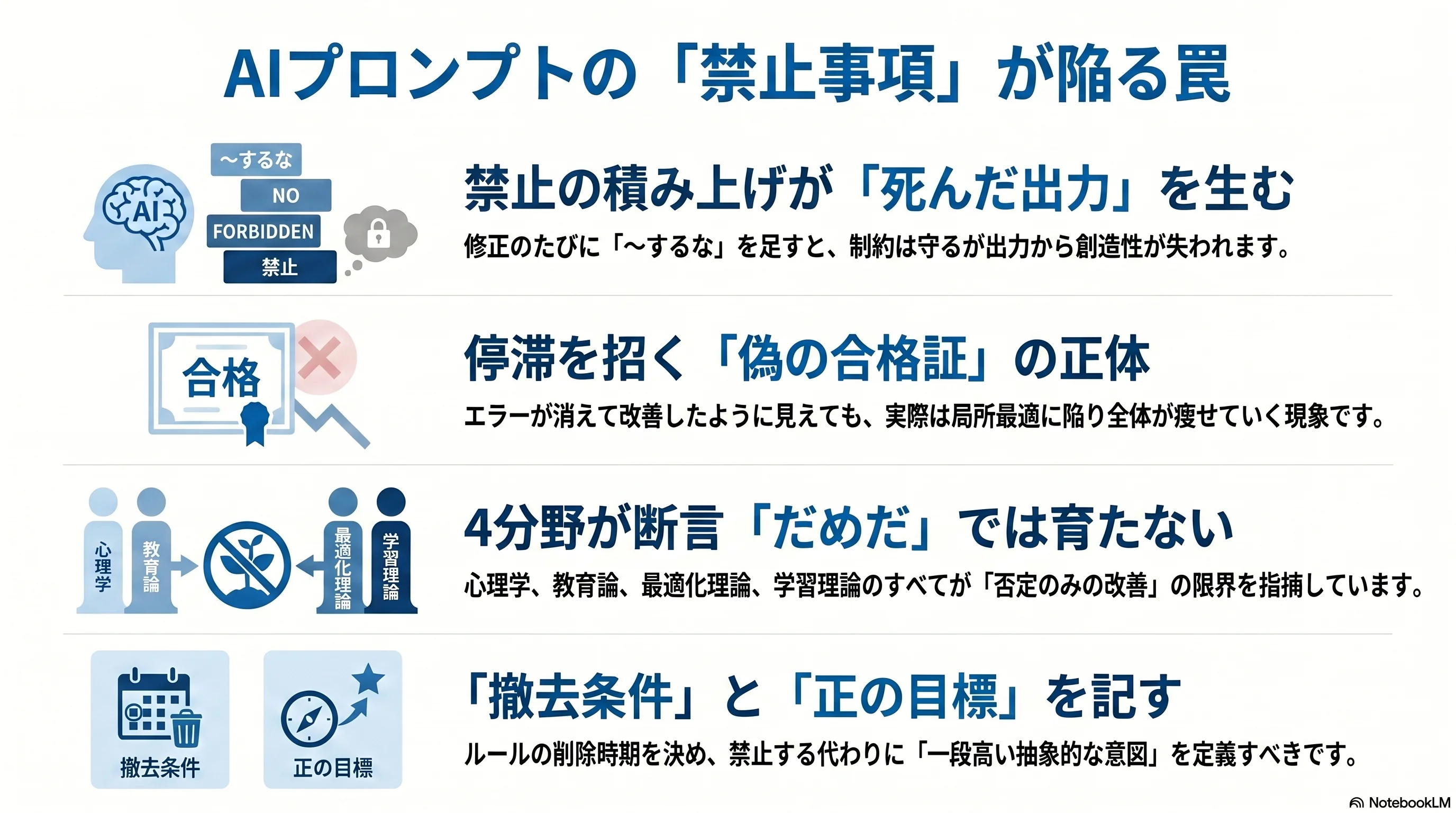
生成された出力が望ましくないたびに、Claude Code は「こうするな」「あれをするな」をプロンプトに足していった。私が訂正したい点を、Claude Code は 禁止条項として書き加える ことで反映する。気がつくと、プロンプトは禁止の山になって、出力からは創作性が抜けていた。個別の禁止は全部守られていて、しかし全体としては死んでいる、という状態。
別の機会には、占いを生成させるプロンプトで、出てくる「悪い回答パターン」を Claude Code が一つずつ禁止しようとした。これも詰んだ。占いタスクのパターンは無限に出てくるので、禁止リストは増え続け、それでもすり抜けが起こる。モグラ叩きの典型。
どちらの場面でも私は気づいて指摘し、Claude Code は方針を切り替えた。だが reject の痕跡が残らないので、別のセッション、別の課題でも、Claude Code は同じ動作 (= 修正 == 禁止を足す) を繰り返す。Claude Code は、プロンプト改善のドメイン知識を持っていないのではないか——そういう疑惑がここで立った。
私たちが私たちで「これは禁止を積みすぎだろう」と分かるのと同じ程度には、Claude Code も気づいていてほしい。だが実物の挙動を見るかぎり、気づいていない。
この疑惑を抱えて、3 つのことを順にやった。
- 「だめだだめだ」で何が起きるか を、各分野が何と言っているかを並べる
- Claude Code が私のために積んだメモリ を grep して、実際にどれくらい禁止だらけか測る
- Claude Code に欠けたドメイン知識を補える OSS があるか探す
その記録。
「だめだだめだ」で何が起きるか — 4 分野が同じ構造を語っていた
Claude Code がやっていた動作を抽象化すると、こうなる。
個別の修正サイクル (A→B→C→D→A) は健全に回って見える。ただし側道で、全体としての出力は痩せていく。そして禁止が出尽くしたとき、訂正可能な箇所が消えて「もう直すとこがない」と感じる——これがあとで何度も出てくる 偽の合格証 だ。
このパターンは Claude Code に特有のものではない。「だめだだめだ」を積み上げるとどうなるかは、独立した 4 分野が独自の語彙で語っていた。
形式学習理論 (Gold, 1967)
E. Mark Gold の identification in the limit。学習者が例を見て仮説を出し、間違えたら直す、というモデルで「有限回の訂正のあとに正しい仮説に収束して以後変えない」状態を到達とみなす。
結論は二つ。(1) 条件が揃えば確かに収束する。(2) しかし学習者は 自分がいつ収束したかを内部から判定できない。さらに、正解が自分の仮説クラスの中になければ絶対に収束しないし、肯定例だけでは収束できないクラスがある——「これは違う」という否定的フィードバックが要る。
つまり「だめだ」は学習に必要だが、「だめだ」だけでは収束を保証できないし、収束しても気づけない。Claude Code が訂正を受けて禁止を足し続けるなら、まさにこの「内部から収束を判定できない」位置にいる。
最適化 (ヒルクライミング)
機械学習の入門で出てくる 局所最適 の話と同じ。「今より良い方向へ一歩」しか動かない素朴な山登りは、本当の頂上 (大域最適) ではなく、近くの低い丘 (局所最大) に登り切って止まる。「もうどっち向いても下りしかない」となって動けなくなる。
これを「失敗を一個ずつ直す」プロセスに当てると、ある時点で どっち向きに直してもスコアが下がる 地点に着く。そこではあらゆる訂正の試みが「悪化」という形で「もう直すところはない」という肯定的な証拠を返してくる。地形が嘘の合格証を発行してくる。
抜け出すには、わざと悪化を許す手——焼きなまし法、ランダムリスタート——が要る。「もっと直す」ではなく「方法を変える」。
社会心理学
人間でも同じ構造が観察されている。
- 白熊効果 (Wegner): 「X を考えるな」という指示は、まず X を表象させてから抑制するため、逆に X が頻出する
- Bad is stronger than good (Baumeister et al., 2001): 同じ強度なら、悪い情報は良い情報より心理的に強く効く
- 5:1 の比率 (Gottman): 関係を保つには、肯定的やりとりが否定的やりとりの 5 倍必要——崩れると批判が方向づけを押し流す
「だめだ」は強く効きすぎる。だから足しすぎる——これは人間が自分で書くときも、Claude Code が代わりに書くときも同じ。
教育・組織論
組織研究では、批判過多のチームで何が起きるかが計測されている。エドモンドソンの心理的安全性——批判が一定量を超えると、失敗の報告そのものが消える。自己決定理論——禁止だらけだと内発的動機が削れて、無難な安全圏に縮こまる。
夫婦関係の研究にも、これと同型の現象を捉えた語彙がある。ゴットマンの「四騎士」——心理学者 John Gottman が、関係を破綻に向かわせる 4 つの行動パターンとして抽出したもので、ヨハネ黙示録の四騎士になぞらえてこう呼ぶ。批判 (Criticism) → 軽蔑 (Contempt) → 防御 (Defensiveness) → 石の壁 (Stonewalling)。とりわけ軽蔑は、離婚を予測する最強の単一指標として知られる。「だめだ」を積み上げると、まず批判の段階に乗り、やがて軽蔑が混じり、相手は防御を始め、最終的に石の壁——会話の経路そのものが閉じる——に至る。
ここで興味深いのは、報告が消えたチームや、石の壁に着地した関係は、表面上 エラーが減って改善したように見える こと。これは形式学習理論の「偽の合格証」と完全に同型だ。社会的にも、地形が嘘の合格証を発行する。
並べてみると、4 分野は同じ核を別の語彙で語っていた。
別言語で語られているが、4 分野は同じことを言っている。「だめだだめだ」だけで人 (またはプロンプト、または組織) は育たない。育っていないのに育ったように見える状態に着地する。
そして、4 分野のどれを覗いても出てくる「だめだ積み上げは局所最適に着地する」というドメイン知識を、Claude Code は明示的に持っていない (少なくとも、私の前で見せる挙動からはそう見える)。だから禁止を積む。
Claude Code が積んだメモリを grep してみた
ここで気づいた——「そもそも、本当に Claude Code は禁止プロンプトを積み上げていたのか」。事故 2 件は印象に残っているが、N=2 では何も言えない。Claude Code の auto memory (= 私の訂正やフィードバックを永続化したファイル群) を直接測ろう。
実測した。~/.claude/projects/<...>/memory/ 配下、私のプロジェクトで Claude Code が積んだメモリファイル全 33 件を grep にかけた。
- 「するな」「禁止」「してはいけない」「don.?t」「never」「avoid」など、禁止形パターンを含むファイル: 6 / 33 = 18%
- そのうち、目視で誤検出 (「するなら」が「するな」+ ら と誤マッチ、設計記述、外部システム仕様など) を除いた純粋な naked prohibition: 3 / 33 = 9%
- 「撤去条件」(「いつこのルールを消すか」) を明示しているファイル: 0 / 33 = 0%
最初の疑惑——「Claude Code は禁止プロンプトを積みがち」——は、データで言うと 強くは裏付けられなかった。9% は「禁止だらけ」と断ずるには低い。実は 7 割以上のフィードバックは、Claude Code がちゃんと正の規約に書き直して保存していた。事故 2 件 (私の印象) と、メモリの実態 (Claude Code の作業の積分) はズレていた。
代わりに、別の問題が決定的に裏付けられた。撤去条件の明示がゼロ。すべてのルールが append-only で、いつ消すかが書かれていない——「正しい」ルールも「もう古い」ルールも、同じ重さでメモリに居座る。Claude Code は禁止を積みすぎてはいないが、いつルールを撤去するかというドメイン知識は持っていなかった。
そしてここで自己診断の罠にも気づいた。この grep の lens は私が自分で設計した。私が会話のなかで作り上げた「naked prohibition」「偽の合格証」という語彙を、私のメモリに、私の判定で当てている。前述の局所最適の話そのものだ。自分が立てた仮説を、自分の作った lens で、自分の管理するサンプルに当てはめて、当たっていると言う——確証バイアスの教科書例。N=33 で base rate は分からないし、採点者独立性もない。
それでもデータは出た。「Claude Code は禁止積みがち」という体感は、少なくとも grep 1 段では裏付かなかった。一方、「Claude Code は撤去条件を書く知識を持っていない」は明確に裏付いた。
Claude Code を補えるツールを 3 つ探した
疑惑——「Claude Code はプロンプト改善のドメイン知識が薄い」——を仮に認めるなら、それを OSS で補えないか。ノウハウない領域は自作スキルより素の OSS を試す、というのが私のルールでもある。3 つ調べた。
Anthropic Prompt Improver (Console 公式)
入力したプロンプトに、Chain-of-thought の明示、XML タグでの構造化、例の標準化、prefill 追加——を 加える。多ラベル分類で精度 +30%、要約で word count 遵守 100% という評価が公開されている。
正解のあるタスク向け。創作の過剰制約には合わない。むしろ既存の naked prohibition があれば、それを CoT つきで丁寧に展開して固定化する可能性すらある。「prompt を長く・冗長に・遅くする」と公式が明記している。Console 限定で、API/CLI からは直接呼べないので Claude Code に挟むのも難しい。
severity1/claude-code-prompt-improver (OSS plugin)
Claude Code の hook に挟まる仕組み。9 個の "nudge" を JSON で宣言し、条件マッチで発火させて、適切なタイミングで context を注入する。「プロンプトを書き直す」ものではなく、「プロンプトから出力までの経路全体を改善する」設計。設計思想は強い——fire wide, self-cancel cheap (false fire のコストは低いから高 recall でいい、各 nudge は条件を最初に書いて自分でキャンセルできるように作る)。
ただし、対象が「fix the bug」「refactor」「implement」のタスク系プロンプトで、Claude Code がプロンプトを書く/直す側に立っているときの伴走者ではない。Claude Code をユーザーに対して矯正する側で、私が想定していた方向 (Claude Code 自身の prompt-writing を支える) と違った。
Promptfoo / DeepEval (eval フレームワーク)
eval セットを作って複数 example で自動採点する。N=1 の単発診断 (= Claude Code が今書いたこのプロンプト、これ大丈夫?) には合わないが、定量検証の本命はこっち。ただし eval セット自体を作る労力が要る。
3 つに共通していたのは、全部「介入する側」「prompt を書き換える側」「自動採点する側」 で、Claude Code がプロンプトを書いている瞬間に「あ、今 naked prohibition を積みかけてる」と気づかせる類のものではなかった。私が想定していた「Claude Code に欠けたドメイン知識を渡す」型のツールは、見つからなかった。空白地帯。
残ったのは語彙だった
ツールは買えなかった。でも 4 分野を巡るあいだに、Claude Code に渡せる (あるいは Claude Code が自分で持っているべき) 禁止を足す代わりに使える正の方策 がいくつか取り出せた。
| 症状 | 対応する正の方策 |
|---|---|
| 無限パターンを全部禁止しようとする | step-back: 原理に一段抽象化 (個別を縛らず、上位の意図で書く) |
| 何を目指してるか分からなくなる | 正の目標仕様: 肯定形で「こうあってほしい」を書く |
| 同じ丘を登り直して中途半端で止まる | アブダクション: 別の山に飛ぶ仮説生成 (パース的) |
| 一つの答えに固執して壊れる | 多保持: 競合仮説を残す (self-consistency, ベイズ的) |
| 過剰修正で創作性・冒険を殺す | 正規化を弱める: 過剰制約の自覚を入れる |
| 守らせたい絶対ルールを文脈に押し込む | 階層配分: 文脈 (memory) ではなく hook / CI / 型に降ろす |
最後の「階層配分」だけ補足する。Claude Code の世界では、ルールを書く層が複数ある——CLAUDE.md (文脈、確率的にしか効かない)、システムプロンプト (強い事前分布、それでも確率的)、PreToolUse フック (決定的、ブロックできる)。「Claude にどんなにお願いしても確率的にしか守らない」種類のルールを、文脈層に書き続けるのがしばしば失敗の根。本当に守らせたいなら層を下ろす。「だめだ」を文脈に書くより、その動作自体をフックで禁止する方が、設計として誠実だ——これも Claude Code が自分から提案してくる類の発想ではなかった。
そして語彙。これがこのプロセスで残った最大の収穫だと思う。
- naked prohibition: 正の規約と対になっていない裸の禁止
- 偽の合格証: 局所最適点で「もう直すところがない」と感じる現象
- 別の山に飛ぶ: 局所最適を抜けるための非局所な一手
- 撤去条件: いつこのルールを消すかを最初に書いておく
- 層配分: memory (確率的) / システムプロンプト (より強い) / フック (決定的) の使い分け
これは概念で、ツールではない。だが概念は、Claude Code が禁止を積みかけた瞬間に、ユーザー側で「あ、今 naked を積もうとしてる」「これ局所最適に登ってるな」と気付くフックになる。Claude Code がドメイン知識を持っていない領域を、ユーザー側の語彙でカバーするための道具箱。
留保: 全部 folklore の域
ここまでに並べた話は、心理学の実証研究と形式理論の定理を、LLM プロンプトに当てはまるはず、と類推したものだ。LLM の禁止プロンプトが定量的に効きにくいことを、N と効果量つきで示した研究を、私はこの記事では引いていない (出始めてはいるが、まだ薄い)。
だから読者として、これらを「定理」として持ち帰ってもらうのは違う。folklore の域だ。
それでも、語彙としては機能する。最初の事故 2 件は、いずれも Claude Code 側に「禁止を足す以外の選択肢」の語彙がなかったから 起きた (ように見える)。ユーザー側が語彙を持っていれば、そこに気づいて reject できる。ドメイン知識のギャップを、語彙で外側から埋める——これが今回の結論で、定理ではなく経験論だが、私の N=2 にはあてはまっている。
冒頭の問いに戻る。
「だめだだめだ」でいい子は育つか。形式学習理論・最適化・社会心理学・教育論が、それぞれの言葉で「育たない」と言っていた。育っていないのに育ったように見える状態に着地して、地形がそれを合格証として発行する。Claude Code は (少なくとも今のところ) この 4 分野のドメイン知識を自分の作法に取り込んでいない。
ツールは買えなかった。だが、Claude Code の手が滑りかけているかをユーザー側で 言語化できる ようになった——それが、この調査の終点だ。