【第4回】エージェントを構築する——スキル委任・agent-creator・article-writer の実践
スキル→エージェント委任パターン、agent-creator による自動生成、article-writer エージェントの構築まで。Claude Code サブエージェント検証シリーズ最終回
← 前の記事: 【第3回】エージェントの設定を理解する——Write vs Edit の罠と権限モデルの全貌前回は、設定ファイルの各項目を一つずつ確認しながら権限モデルの全体像を明らかにしました。Write(...) は無効なルール名で Edit(...) が正解だという発見、同期と非同期で権限の挙動が変わる罠、settings.local.json のホットリロードは正常に機能する——丸一日かけてようやく全貌が見えた回でした。
3回分の知識が揃いました。概念を理解し(第1回)、性質を確認し(第2回)、設定を把握した(第3回)。
今回は、これらを使って実際にエージェントを組み立てます。「設定の理解が、構築に変わる」回です。
スキル→エージェント委任パターン
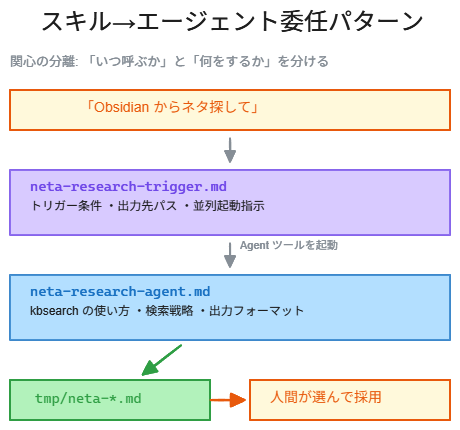
前回の実験中に、ふと気になったことがありました。
私: ところでサブエージェントの発火はスキルみたいに description に依存するの?
Claude Code: いいえ。サブエージェントは自動発火しません。確実に使わせたいなら、スキルのプロンプト内で Agent ツールを呼ぶよう指示するのが正解です。
私: コマンドから発火とかもできる?
Claude Code: はい。
/neta-research-triggerみたいなスラッシュコマンドを作って、その中でエージェント呼び出しを指示すればいい。
私: コマンドって Claude も使えるんだっけ?
Claude Code: コマンドはユーザー専用です。Claude 側から自動的に呼べるのはスキルだけ。
私: じゃあスキルでエージェント発火を書けばいいってこと?
Claude Code: そうです。スキルのプロンプト内で「neta-research-agent エージェントを使え」と指示するだけ。スキルは「プロンプト注入」なので、注入されたテキストに「Agent ツールを使って neta-research-agent を呼べ」と書いてあれば、Claude はそうします。
私: そうすると neta-research-agent と neta-research-trigger かな。
Claude Code: いい整理ですね。エージェント(実行エンジン)とスキル(発火トリガー)の分離。コマンドも合わせて3点セットで作りましょう。
こうして生まれた neta-research-trigger スキルの実際の定義を見てください。
---
name: neta-research-trigger
description: |
Obsidian ナレッジベースから yatmita.com の記事アイデアを探す。
「Obsidian から探して」「ナレッジベースからネタ」「vault から記事候補」と言ったときに使う。
user_invocable: false
---user_invocable: false は自動トリガー型の設定です。description に書いたキーワードにユーザーの発話が一致したとき、自動的に発動します。
スキルの本文にはこう書いてあるだけです。「neta-research-agent エージェントを Agent ツールで起動してください」と。スキルは何もリサーチしません。ただエージェントを起動するよう、メインのコンテキストに指示を注入するだけです。
ここでトリガーの衝突問題が起きました。
私: ネタという言葉に2つとも反応するんじゃない?
Claude Code: 確かに。neta-research-trigger と yatmita-draft、両方の description に「ネタ」が入っている。
私: こっちはもっと明示的に「Obsidian から探して」みたいなときにしたら。
neta-research-trigger のトリガーを Obsidian 関連のキーワードに限定しました。「ネタ探して」で yatmita-draft が動き、「Obsidian からネタ探して」で neta-research-trigger が動く——棲み分けが明確になりました。
フローはこうなります。
ユーザー発話 → スキルが発動(メインコンテキストにテキスト注入)
→ Agent ツールで neta-research-agent を起動
→ エージェントが独立コンテキストで kbsearch を実行
→ 結果を tmp/ にファイル出力
→ メインに戻りユーザーに要約報告
関心の分離、というパターンです。
スキルは「いつ・どう呼ぶか」だけを知っています。自動トリガーの条件、出力先のパス規約、複数ドメインなら並列起動の指示——これはスキルに書きます。エージェントは「何をするか」だけを知っています。kbsearch の使い方、検索キーワードの戦略、出力フォーマット、品質ゲート——これはエージェントに書きます。
もう一つ、候補をそのまま正式なネタフォルダにするかどうかも議論しました。
私: やっぱり人間がリサーチから判断して切り出したほうがいいかしら。
Claude Code: そうですね。ネタ探しは「何が面白いか」の判断が必要で、それは人間の感性の仕事。
neta-research-trigger は /tmp/ に候補を出すだけ。人間が選んで、yatmita-draft で正式なネタフォルダに切り出す——この判断ポイントを残す設計にしました。
なお、user_invocable: false のスキルとは別に、/neta-research-trigger というスラッシュコマンド版も作りました。こちらは domain 引数を渡せます。自動トリガーは「何を探しているか雰囲気で察してほしいとき」、スラッシュコマンドは「明示的に特定ドメインを指定したいとき」——場面によって使い分けています。
agent-creator で自動生成を試した
スキルとエージェントの構造が分かってきたころ、公式プラグインの plugin-dev:agent-creator スキルを試してみました。エージェント定義を自動生成してくれるスキルです。
手動で書いた neta-research-agent.md は約60行でした。同じ要件を agent-creator に伝えたら、約150行の定義を生成しました。
agent-creator が追加してくれたのは、入力バリデーション(ドメイン名の妥当性チェック)、エッジケース処理(kbsearch 接続失敗時の振る舞い)、出力フォーマットの詳細なテンプレートなど。手動では省いていた「親切な」指示が網羅されていました。
最初の叩き台を作るのには便利です。ゼロから書くより、生成されたものを削ぎ落とす方が早いこともある。
ただ、注意点があります。agent-creator は「良いエージェント定義を書く」ことに最適化されています。結果として、CLAUDE.md に書いてあるコンテンツルール(文体ガイドライン、法的表現の規約)まで定義に書き込もうとします。エージェント定義とプロジェクト共通ルールが二重になって、管理コストが上がります。
NOTE
追実験(2026-03-09)で判明 CLAUDE.md・MEMORY.md はサブエージェントに自動で継承されます(第3回の追実験で検証済み)。agent-creator が書き込もうとするプロジェクトルールの多くは、そもそもエージェントが最初から持っている情報です。削ぎ落とすべき理由がもう一つ増えました。
agent-creator は出発点として使い、最終的に自分で責務を整理して削ぎ落とす——この使い方が適切だと感じました。
article-writer エージェントの構築
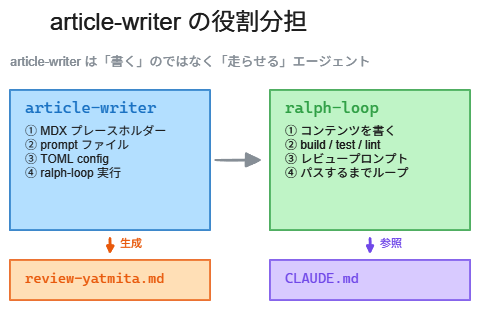
ネタ探しの次は「記事を書く」エージェントを作りたくなりました。
私: 次に yatmita で既存ドメインで記事を ralph-loop で書くエージェントを作りたいと思う。いやこの流れだとエージェントでもいいのかな?
Claude Code: 記事執筆なら ralph-loop の方が向いてると思います。build/test/lint のフィードバックループが核心機能で、これは ralph-loop の存在意義そのもの。サブエージェントが活きるのは ralph-loop の前段階です。
私: それでやってみよう。
正確に言うと、「記事の中身を書く」エージェントではありません。私が作った article-writer.md の frontmatter はこうです。
---
name: article-writer
description: "yatmita.com の記事を ralph-loop CLI で書くエージェント。ドメイン・記事タイプ・slug・参考資料パスを指定して起動する。"
tools: ["Bash", "Read", "Write", "Glob", "Grep"]
---このエージェントの仕事は4つだけです。MDX プレースホルダーを作る、prompt ファイルを生成する、TOML config を生成する、ralph-loop を実行する——以上です。
コンテンツを書くのは ralph-loop です。品質を担保するのは review-yatmita.md というカスタムレビュープロンプトです。article-writer のシステムプロンプトには「良い文章を書け」とは一切書いていない。それはエージェントの仕事ではないからです。
そして、コンテンツルールについても同じです。生成する prompt ファイルに「CLAUDE.md を読むこと」と書くだけにしました。CLAUDE.md を更新すれば、以降の全記事執筆に自動的に反映されます。ルールは一か所で管理する——agent-creator の失敗から学んだことです。
ハマったポイント: description の YAML パース失敗
article-writer を作るときに、一つハマりました。
最初は description を詳しく書こうとしました。複数行にわたって役割・手順・注意点を書いたんです。
description: |
yatmita.com の記事を ralph-loop CLI で書くエージェント。
MDX プレースホルダー・prompt ファイル・TOML config を生成し、
ralph-loop を実行する。コンテンツは書かない。これで YAML のパースに失敗しました。エラーメッセージは不親切で、一見すると構文エラーに見えない。なぜ動かないのか原因特定に時間がかかりました。
解決策は description を1行に短縮することでした。詳しい説明は本文(システムプロンプト)に書けばいい。
第3回で「description はエージェントの識別用と同時に自動トリガーの条件宣言でもある」と整理しました。識別用なら1行で十分です。詳しい指示はシステムプロンプトに書く——この分担が正しい。理解していたはずなのに、実装では逆をやっていました。
ralph-loop との役割分担
ralph-loop は、prompt ファイルに従って記事を生成し、build/test/lint が通るまでループするツールです。カスタムレビュープロンプト(review-yatmita.md)を設定しておくと、生成した記事の正確性・法的表現・読者配慮などをチェックしてくれます。
LLM が書いた記事を LLM がレビューする構造です。完璧ではないですが、明らかなミス——効能の断定、専門用語の説明不足——は拾ってくれます。
article-writer はこのループを起動するだけ。scaffolding engineer(足場を組む人)として設計しました。コンテンツの品質には一切責任を持たない代わりに、準備と実行だけは確実にやる。
シリーズを振り返る
12回の実験を経て、何が分かったか改めて整理します。
- 第1回: スキル・エージェント・Task の概念整理。Hello World で「別の人に仕事を頼む」感覚をつかんだ。カスタムエージェントを初めて動かして、セッション再起動が必要という罠にはまった
- 第2回: 戻り値はテキストのみ。ネスト呼び出しは不可(初回は1時間ハングしたが追実験では即エラーに改善)。ファイル出力パターン(結果をファイルに書き出してパスだけ返す)という実用解を発見した。並列実行はほぼ完全並列(起動ラグ約1秒のみ)
- 第3回:
Write(...)は無効なルール名でEdit(...)が正解——丸一日溶けた。同期では手動承認があるので動くが、非同期では事前許可が必須。ホットリロードは正常に機能する。CLAUDE.md・MEMORY.md はエージェントに継承される——ルールの二重管理は不要 - 第4回(今回): スキル→エージェント委任で関心を分離する。agent-creator は叩き台作りに便利だが、最終的は自分で削ぎ落とす。article-writer は「書く」のではなく「走らせる」エージェントとして設計する
振り返ってみると、どれも「やってみないと分からなかった」ことばかりです。
ドキュメントを読んだだけでは、Write(...) が無効ルール名だとは分かりませんでした。実際にはまって、調べて、ようやく公式ドキュメントの一行が目に入った。ネスト呼び出しが1時間ハングすることも、試してみるまでは想像もしていませんでした。
サブエージェントは、AI が AI を使う最初の一歩です。1つの AI に全部やらせるのではなく、役割を分けて協力させる。人間のチーム開発に似ています——専門家に委任して、結果を受け取る。
あなたも、まずは Hello World から始めてみてください。汎用エージェントに「kbsearch で何か調べて」と投げるだけでいい。その21秒が、「別の自分に仕事を頼む」感覚の最初の一歩になります。
「やってみた」から「使いこなす」へ——それがこのシリーズを通じて起きたことです。
NOTE
追記(2026-04-27) 「最終回」と書きましたが、その後さらに発見がありました。公式エージェントを自作スキルでラップする設計パターンについて 第5回 を書いています。